| Improving COVID-19 Forecasts | COVID-19 Temporal Knowledge Graph | Building a Time-Series Foundation Model | Multi-modal Time-Series Forecasting |
Our Approach to Neuro-symbolic Computing
Neurosymbolic Artificial Intelligence (AI) refers to AI systems that seek to integrate (1) neural network-based methods with (2) symbolic, knowledge-based approaches [Sheth2023]. We believe (1) represents low-level, and data-intensive learning and (2) captures high-level, and reasoning-intensive learning. (1) is very successful in building large models for language and vision, and learning patterns in the input data. However, their mostly black-box nature does not enable sufficient transparency and explanability. However, a hybrid approach that incorporates (2) can better mimic human cognition (e.g., semantic memory) than (1) alone and enable the explainability of model output.
Consider the task of pandemic (novel pathogens) forecasting. In this task we expect a model to predict the number of infections, hospital visits, and mortality rates in the near future. Neural network-based models can learn (1) time-series patterns of a pandemic (e.g., COVID-19) from past data. Potentially time-series data from other non-stationary or stationary diseases (e.g., flu, RSV, etc.) and even from other domains (e.g., stock market, electricity consumption, etc.) can help to learn time-series patterns. However, this approach does not involve (2) a reasoning capability (e.g., it is possible to reason that a spike in the forecast will occur if a high virulence variant has emerged). A Neuro-Symbolic AI-based approach aims to incorporate both phenomena (1 and 2) to make more accurate and explainable forecasts as depicted in the figure below.
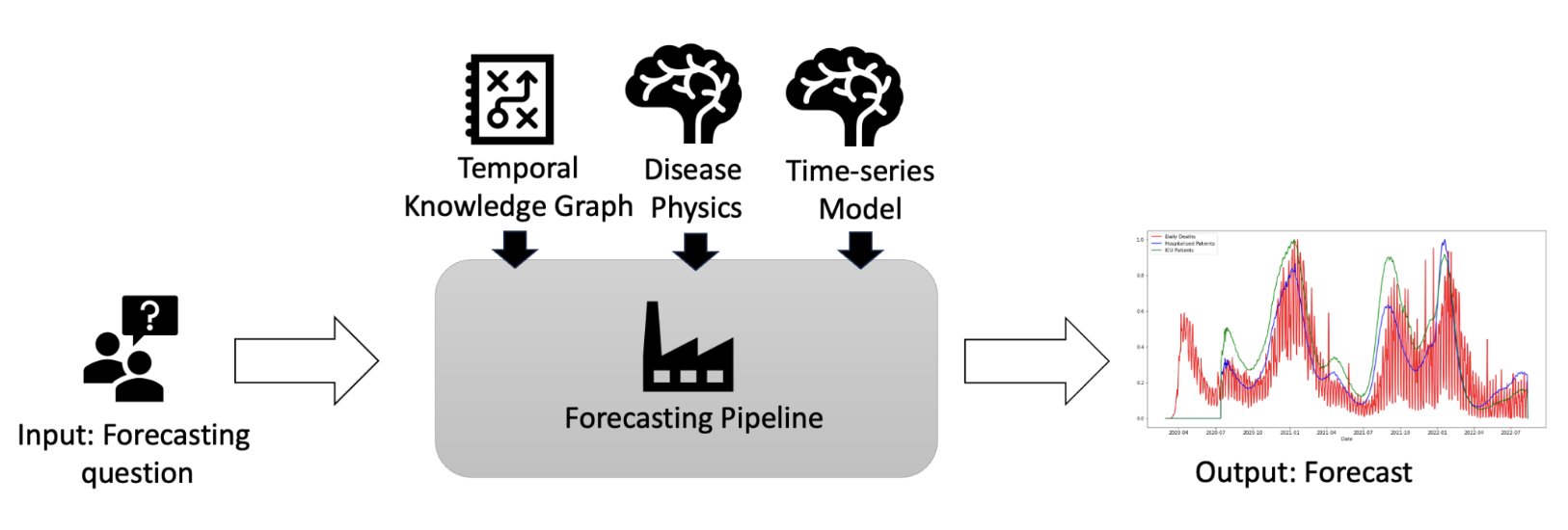
Our Neurosymbolic approach to COVID-19 forecasting involves the following individual projects:
1- Improving COVID-19 Forecasts: In this project we study which neural network-based model performs better against traditional ensemble methods published by CDC. This project also informs Project (3) below for a backbone architecture for our foundation model.
2- COVID-19 Temporal Knowledge Graph: This project aims to generate a very large Temporal Knowledge Graph by using text-extraction techniques from scientific papers as well as news archives on COVID-19. This knowledge graph constitutes our symbolic representation of a hybrid model.
3- Building a Time-Series Foundation Model: This project aims to build a foundation that is trained on a collection of time-series data from various domains including disease, stock market, energy consumption, etc.
4- Multi-modal Time-Series Forecasting: In this project we aim to integrate both symbolic (2) and neural (3) approaches to build a hybrid architecture for pandemic forecasting. We explore alignment as well as meta-learning among different modalities (text, image, graph) as well as different models (time series, language, knowledge).
COVID-19 Forecasts: A Comparison with CDC Models Permalink
This research project aims to enhance the accuracy of COVID-19 forecasting models. It nvolves a detailed analysis and comparison of COVID-19 forecasts with the models provided by the Centers for Disease Control and Prevention (CDC).
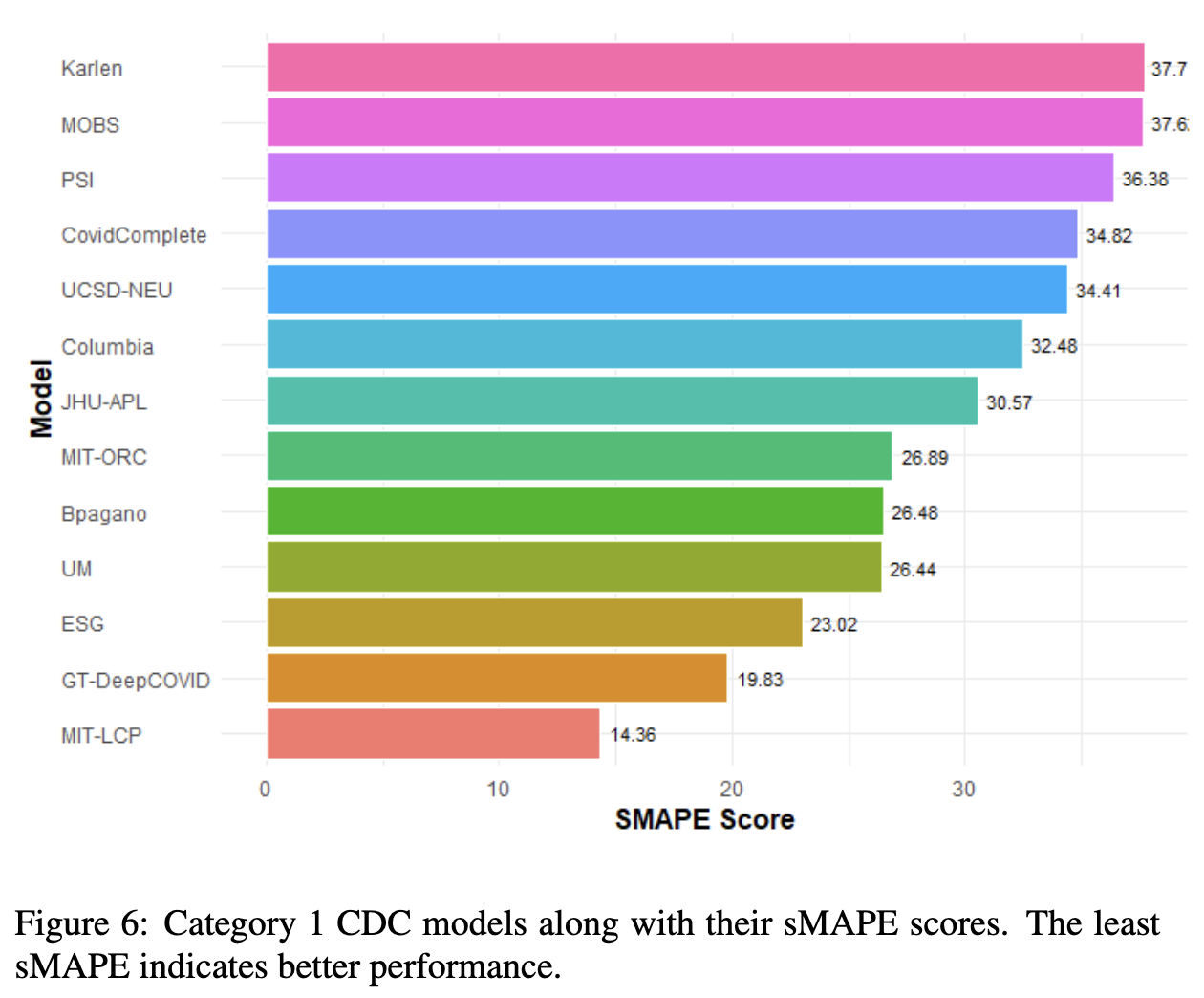 (Click on picture icon to see a representative diagram)
(Click on picture icon to see a representative diagram)
Representative Publications:
-
S. Rana, N. H. Barna, and J.A. Miller
Exploring the Predictive Power of Correlation and Mutual Information in Attention Temporal Graph Convolutional Network for COVID-19 Forecasting
Proceedings of the 12th International Conference on Big Data (BigData 2023), Lecture Notes in Computer Science (LNCS, volume 14203), Honolulu, Hawaii (September 23-25, 2023) pp. 18-33 Springer Conference
-
M. Toutiaee, X. Li, Y. Chaudhari, S. Sivaraja, A. Venkataraj, I. Javeri, Y. Ke, I. B. Arpinar, N. Lazar, and J. A. Miller
Improving COVID-19 Forecasting using Exogenous Variables
Proceedings of the 7th ACM KDD Workshop on Mining and Learning from Time Series (MileTS 2021) Virtual/Singapore (August 2021) pp. 1-6 arXiv Conference
COVID-19 Temporal Knowledge Graph Permalink
COVID-19 Temporal Knowledge Graph is a data structure that organize pandemic-related information in a connected graph format with time-stamps, enabling researchers and healthcare professionals to easily explore and analyze diverse data sources for insights and solutions in the fight against COVID-19. It provides a comprehensive, interconnected view of information, improving data integration and decision-making processes.
A wave of progress on multivariate time series forecasting has been recent and appears to be heating up with the use of advanced deep learning architectures. Work has started to establish further improvements using Knowledge Graphs and Large Language Models. Our efforts focus on building a Temporal Knowledge Graph with scientific literature, such as the CORD-19 dataset for COVID-19 and news archives. A complete investigation of how this can help with time series forecasting or related problems of time series classification or anomaly detection will take some time. Analysis of the features/factors influencing the course/time evolution of a pandemic may be conducted with the help of LLMs. New research can more quickly be suggested to fill gaps in existing knowledge. Established knowledge can be associated with Knowledge Graphs or Temporal Knowledge Graphs. We are experimenting with multiple ways in which knowledge can be used to improve forecasting.
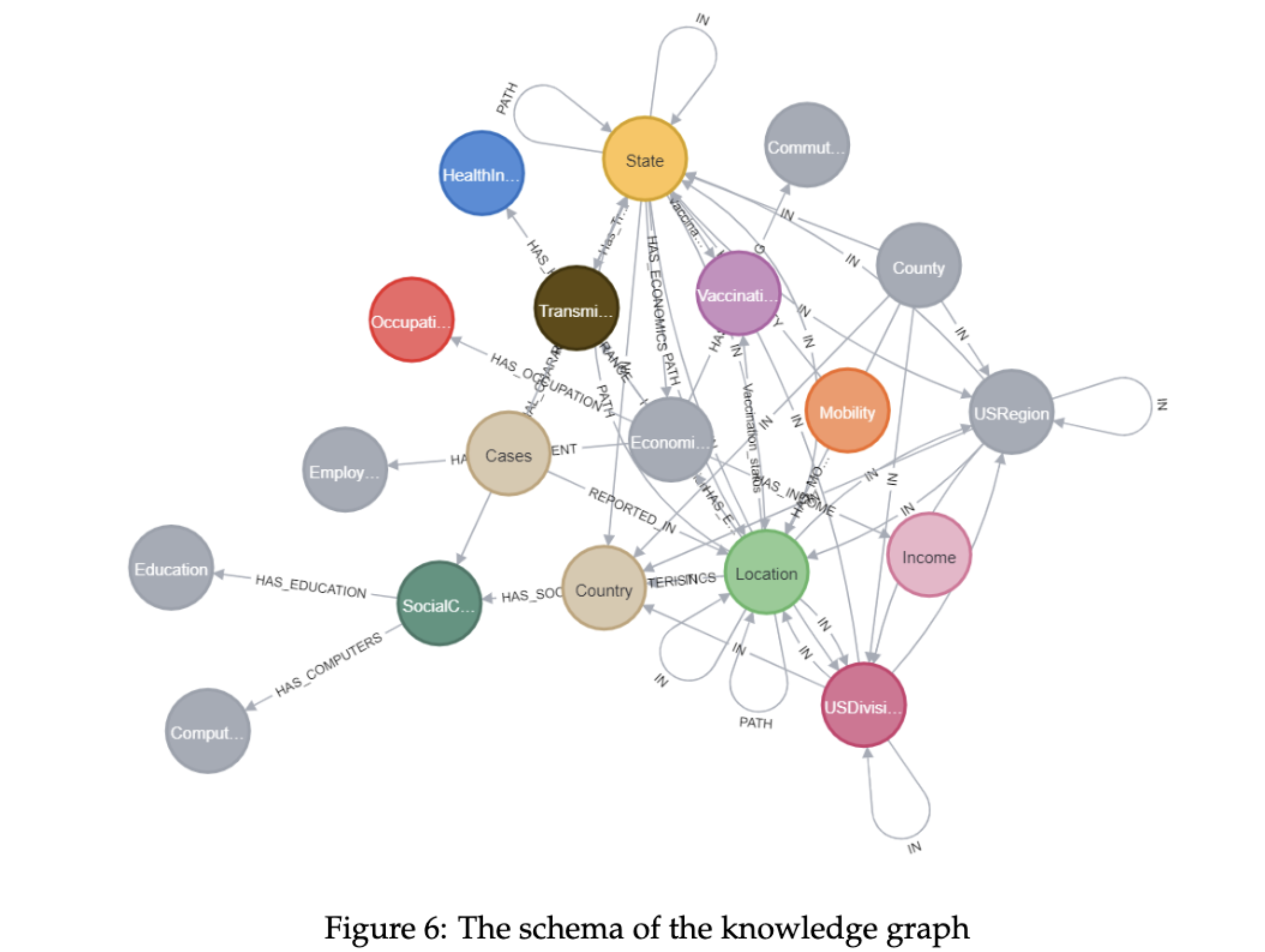 (Click on picture icon to see a representative diagram)
(Click on picture icon to see a representative diagram)
Representative Publications:
-
J. A. Miller, N. H. Barna, S. Rana, I. B. Arpinar, and N. Liu
Knowledge Enhanced Deep Learning: Application to Pandemic Prediction
The 9th IEEE International Conference on Collaboration and Internet Computing, November 1-3, 2023, Atlanta, GA Talk Conference
Building a Time-Series Foundation Model Permalink
Foundation models are being created for several modalities of data and time series data are no exception. During the Fall of 2023, several foundation models for time series data were created and tested. They show promise for providing more accurate and robust forecasts as well as potential for greater explainability. At our lab we are testing multiple options for backbone models as well as different choices for architectural elements. Although successful elements from LLMs are a good starting point, additional research is needed to optimize them for time series data.
Representative Publications:
-
J. A. Miller, M. Aldosari, F. Saeed, N. H. Barna, S. Rana, I. B. Arpinar, and N. Liu
A Survey of Deep Learning and Foundation Models for Time Series Forecasting
arXiv preprint arXiv:2401.13912, 2024 arXiv Journal
Multi-modal Time-Series Forecasting Permalink
We explore modeling time series data with textual data. It is challenging to build time series foundation models that are comparable to existing large language models since: (1) unlike natural languages, existing time series data lacks the inherent semantic richness; (2) the semantics in time series data are often heavily domain-specific (e.g., the modeling of electrocardiogram signals would provide little help in predicting stock prices). There are several potential benefits of the multi-model modeling: (1) textual data can provide essential context that is not captured in the raw time series data; (2) textual semantics can provide domain-specific knowledge that enhances the model’s interpretability; (3) textual data can introduce additional features and dimensions of variability, which can help in training more robust and generalizable models. In this way, text-enhanced time series models can be more easily transferred across different tasks (e.g., classification, forecasting, anomaly detection) and domains.
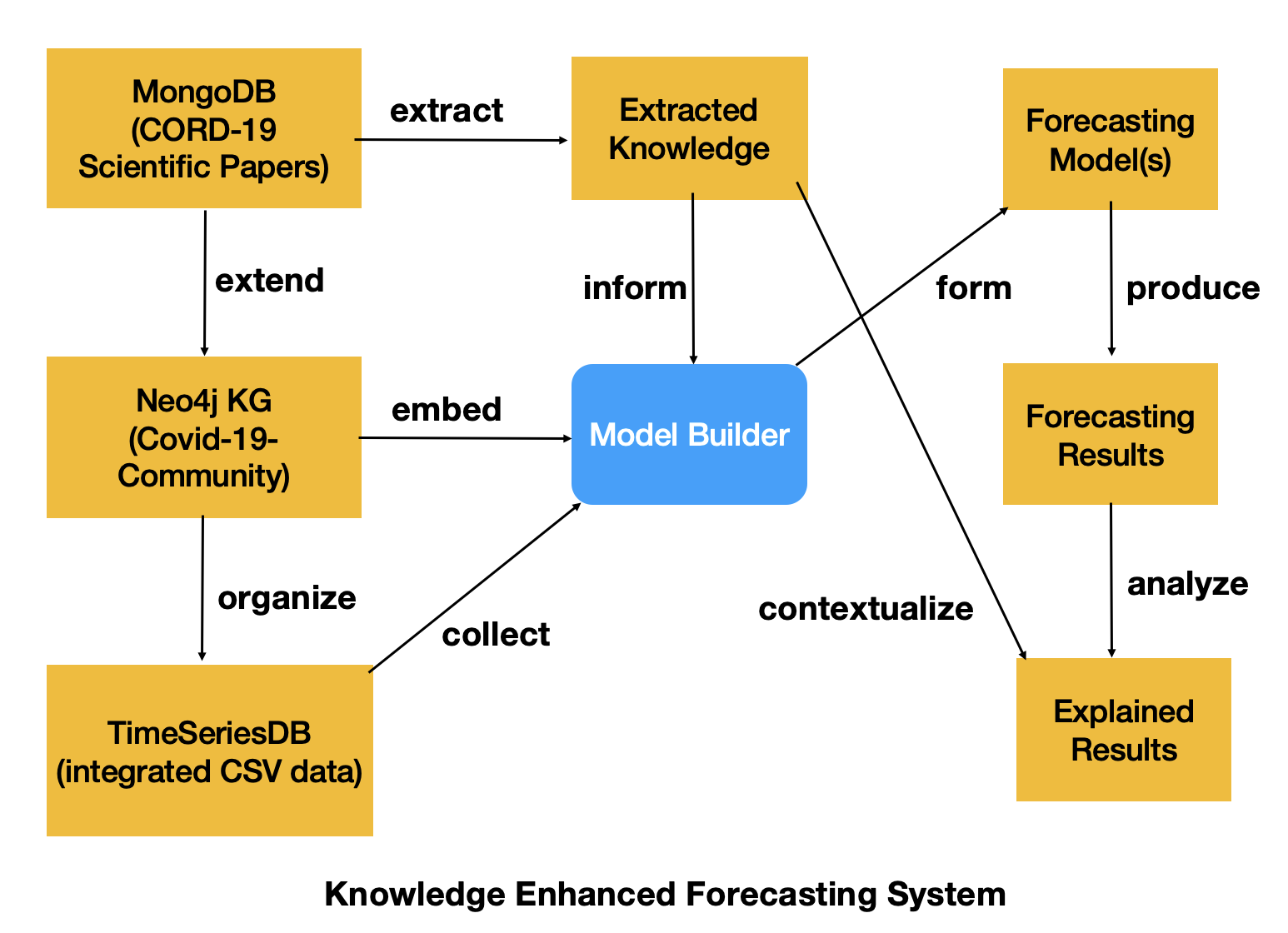 (Click on picture icon to see a representative diagram)
(Click on picture icon to see a representative diagram)
Representative Publications:
-
J. A. Miller, N. H. Barna, S. Rana, I. B. Arpinar, and N. Liu
Knowledge Enhanced Deep Learning: Application to Pandemic Prediction
The 9th IEEE International Conference on Collaboration and Internet Computing, November 1-3, 2023, Atlanta, GA Talk Conference